


In November 2022 we released GuardDog, an open source project originating from an internship at Datadog to identify malicious PyPI packages. Later in February 2023 we released GuardDog 1.0 with support for npm and better heuristics. Then in August 2024 we introduced GuardDog 2.0 with support for custom rules, Golang modules, and YARA scanning.
Today we're excited to announce GuardDog 3.0, which brings major changes and enhancements.
Scanning with YARA instead of Semgrep
GuardDog has historically used Semgrep to run source code heuristics. Semgrep is a great tool for building accurate SAST detections, but we found several issues when using it to scan malicious code at scale: it consumes a lot of memory on large files and runs slowly on packages with many files, partly because it spawns a new process for every scan. Semgrep was built as a CLI rather than an efficient library for running scans programmatically. Our Semgrep rules also tended to be too narrow: they overfit specific examples of malicious code, which made new malware harder to identify.
For these reasons, we moved away from Semgrep and migrated our rules to YARA, which we run with yara-python. yara-python is an efficient Python library for YARA that invokes native code through a CPython extension.
A new risk scoring engine and ruleset
But the rule engine was only part of the problem. This section describes where GuardDog 2.0 fell short and how GuardDog 3.0 takes a more opinionated stance on whether a package is likely malicious or benign.
Where GuardDog 2.0 fell short
GuardDog 2.0 displayed a finding for each Semgrep rule match, with no prioritization, correlation, or confidence that the scanned package was malicious. That design is a problem: GuardDog rules are heuristics, meant to be read as weak signals rather than definitive proof of maliciousness.
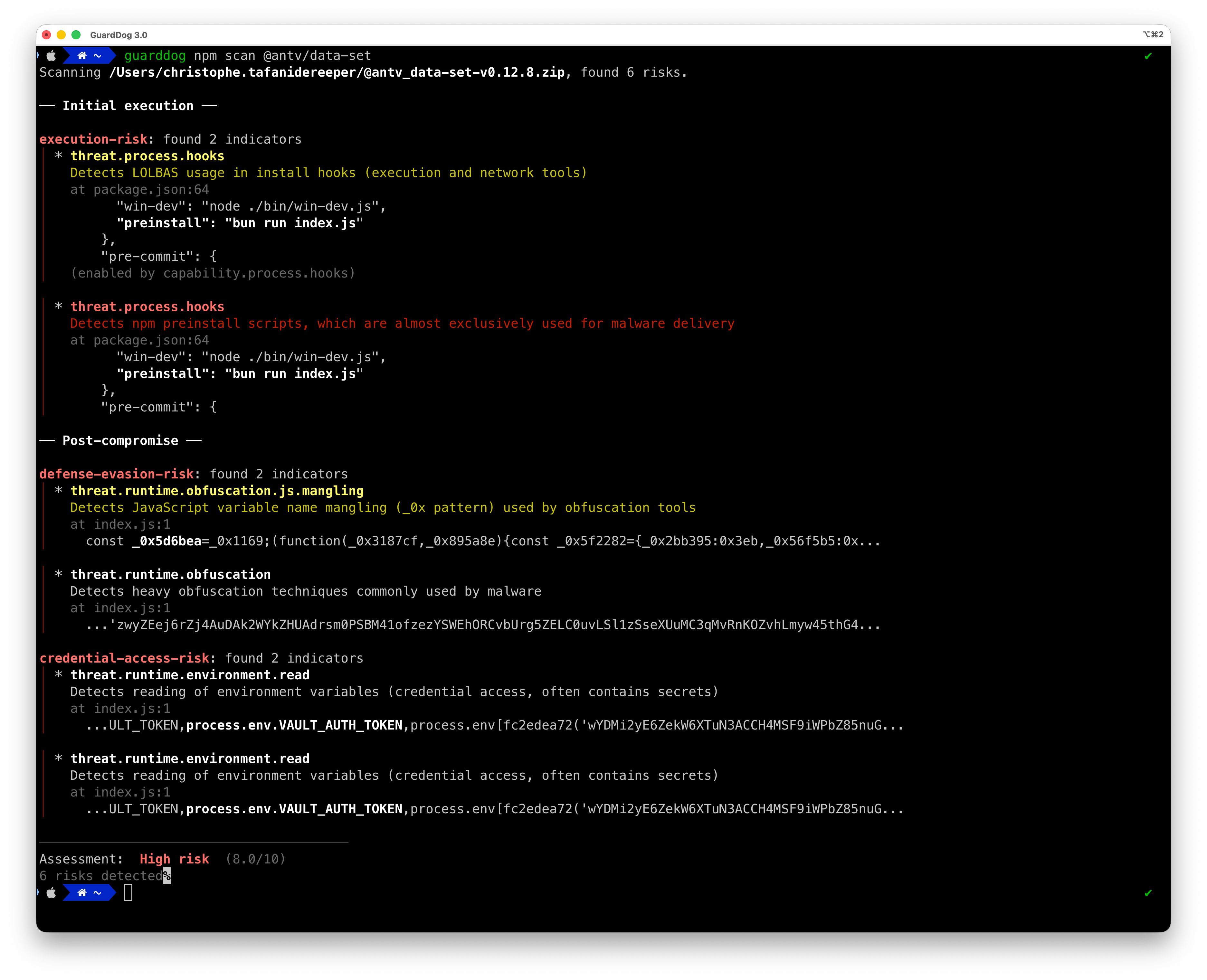
Anatomy of a malicious package
To design the GuardDog 3.0 risk engine, we took a step back and considered how a typical malicious package works:
Unusual metadata. Malicious packages may have names that resemble a legitimate popular package, or high version numbers pointing at attempts to exploit dependency confusion. Legitimate packages that have been backdoored may have a mismatch between package.json/requirements.txt on GitHub and npm/PyPI, for instance when an attacker adds a malicious dependency to the package.json file on PyPI, without reflecting the change on GitHub.
Execution vector: Pre/post-install scripts, or injected code in the setup.py file.
Credential access: Read sensitive credentials from the filesystem or environment variables. Most developers' workstations have long-lived credentials available, so malware typically attempts to access them.
Exfiltration: Upload credentials to an attacker-controlled location, for instance by performing an HTTP request with stolen credentials as a payload.
Second-stage: Pull a second-stage payload from an attacker-controlled location and execute it.
Persistence: Inject code in standard startup locations such as .bashrc or Windows registry keys, so the malicious code still runs even when the malicious package is uninstalled or the machine is restarted.
We concluded that malicious packages typically exhibit identifying characteristics across multiple stages of the attack lifecycle.
Identifying risks
GuardDog 3.0 starts by running two types of YARA rules:
- Rules that identify capabilities. These are not necessarily malicious, and indicate what a package can do. For instance,
capability.network.outbound(perform outbound network calls), orcapability.runtime.clipboard(access the clipboard's content). - Rules that identify threat indicators, such as domain names with suspicious extensions, sensitive file names, deobfuscation routines, and sensitive environment variable names.
Then, GuardDog combines these two layers to identify code locations where a package can, and seems to be performing malicious actions.
Quantifying risk
The next step is to compute a risk score that estimates the probability that a package is malicious. We combine risks using the following factors:
| Factor | Description | Score weight |
|---|---|---|
| Maximal severity | Highest severity risk identified | 30 % |
| Completeness of attack chain | Presence of complete attack stages across initial access, post-compromission activity, and exfiltration | 20 % |
| Specificity | How specific to typical malware matched code is, as indicated by matched rules. In other words, this expresses confidence that matched code is malicious in isolation | 30 % |
| Sophistication | Estimate of the sophistication of the attack chain, aggregated across several rules | 20 % |
We express the output score on a scale of 10:
| Overall risk score | Assessment |
|---|---|
| 0 to 5 | Low risk, likely benign |
| 5 to 7 | Medium risk, should be considered suspicious |
| 7 to 10 | High risk, likely malicious |
Built-in sandboxing with nono-py for defense in depth
As security engineers, we have to accept a humbling truth: the software we write can have flaws, even when we build it carefully. Over the years, the community has reported several vulnerabilities to us that could have let an attacker craft a specific npm or PyPI package to read or write arbitrary files, or even gain remote code execution on the machine running GuardDog.
To protect against these attack vectors, we've integrated the Nono sandbox into the scanning process through its programmatic interface, nono-py. While nono is most commonly used to sandbox AI agents, we use it here purely for its sandboxing primitives, applied to the scanning process itself. By default, with no prerequisites, the scanning process runs isolated in a sandbox with restricted network and filesystem access. Sandboxing covers both extraction and YARA scanning.
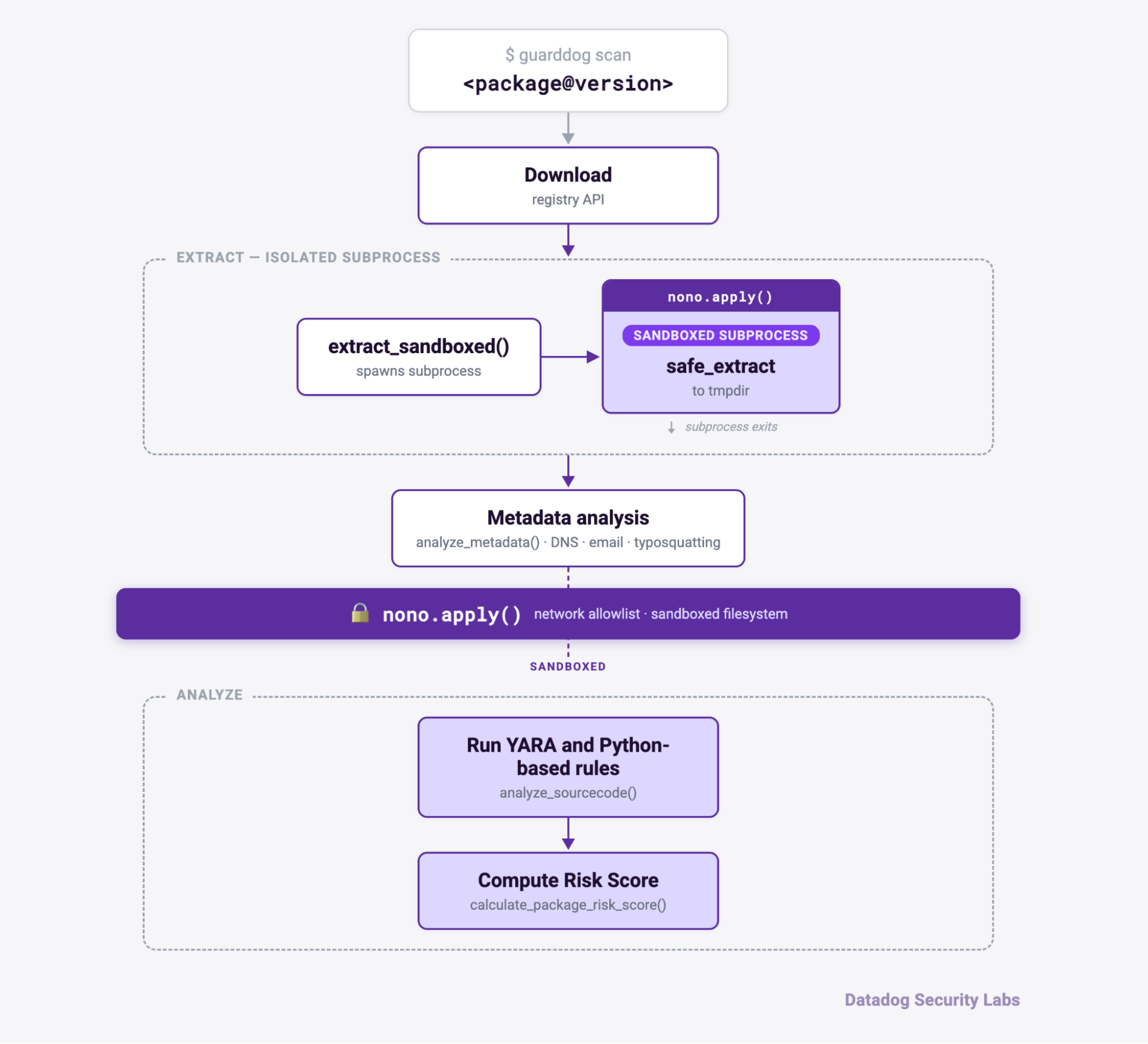
The code below shows roughly how we sandbox the extraction process:
import nono_py as nono
# Main extraction function
def extract_package(package):
apply_sandbox()
return do_extract_package(package)
# Applies the Nono sandbox to the current process
# Once you're inside, you cannot disable it
def apply_sandbox():
caps = nono.CapabilitySet()
for path in _get_common_read_paths():
caps.allow_path(path, nono.AccessMode.READ)
caps.block_network()
nono.apply(caps)
log.info("Sandbox: applied")
def do_extract_package(package):
# Logic for extracting a package to the local filesystem
The sandbox is transparent to the user. Even if an attacker exploits a vulnerability in GuardDog, they can't fully compromise the machine where it runs.
On environments where Nono isn't supported, pass the --no-sandbox flag to disable it.
Evaluating performance
"Is it working?" is a common question in software engineering. "Is it still working?" is even more common, and more painful, in fast-paced projects. We wanted to know how well GuardDog 3.0 performs and to build a way to measure that continuously.
What are we measuring?
For GuardDog, "performing" means:
- Correctly identifying malicious packages (true positives)
- Correctly classifying non-malicious packages as non-malicious (true negatives)
- Minimizing the number of malicious packages missed (false negatives)
- Minimizing the number of legitimate packages incorrectly classified as malicious (false positives)
More specifically, the metrics we're looking at are:
- Precision: When GuardDog classifies a package as malicious, how often is it right?
- Recall: What percentage of known malicious packages does GuardDog classify as such?
Precision and recall are in tension by definition: you can trade one for the other. A naive tool that flags every package as malicious has 100% recall (it finds all known malicious packages) but low precision. One that flags every package as benign has 0% recall. We therefore also measure the F1 Score and the Matthews correlation coefficient (MCC), which combine precision and recall into a single number.
Our evaluation plan is as follows:
-
Run GuardDog against a mixed, labeled set of known-good and known-malicious packages, then measure how many packages it flagged as malicious actually were (precision).
-
Run GuardDog against a set of known-malicious packages, and measure how often it classifies them as malicious (recall).
Using open datasets for evaluations
With a strategy in mind, we needed a dataset. We turned to our own malicious packages dataset, an open collection of more than 27k (and counting!) malicious packages we've found in the wild.
There's a catch: many of these 27k packages are extremely similar or even identical, which can bias our evaluation set. If we sample 1,000 malicious packages and most of them are near-duplicates, the results mean little. We therefore cluster the malicious packages with the TLSH algorithm first, then sample a fixed number of clusters.
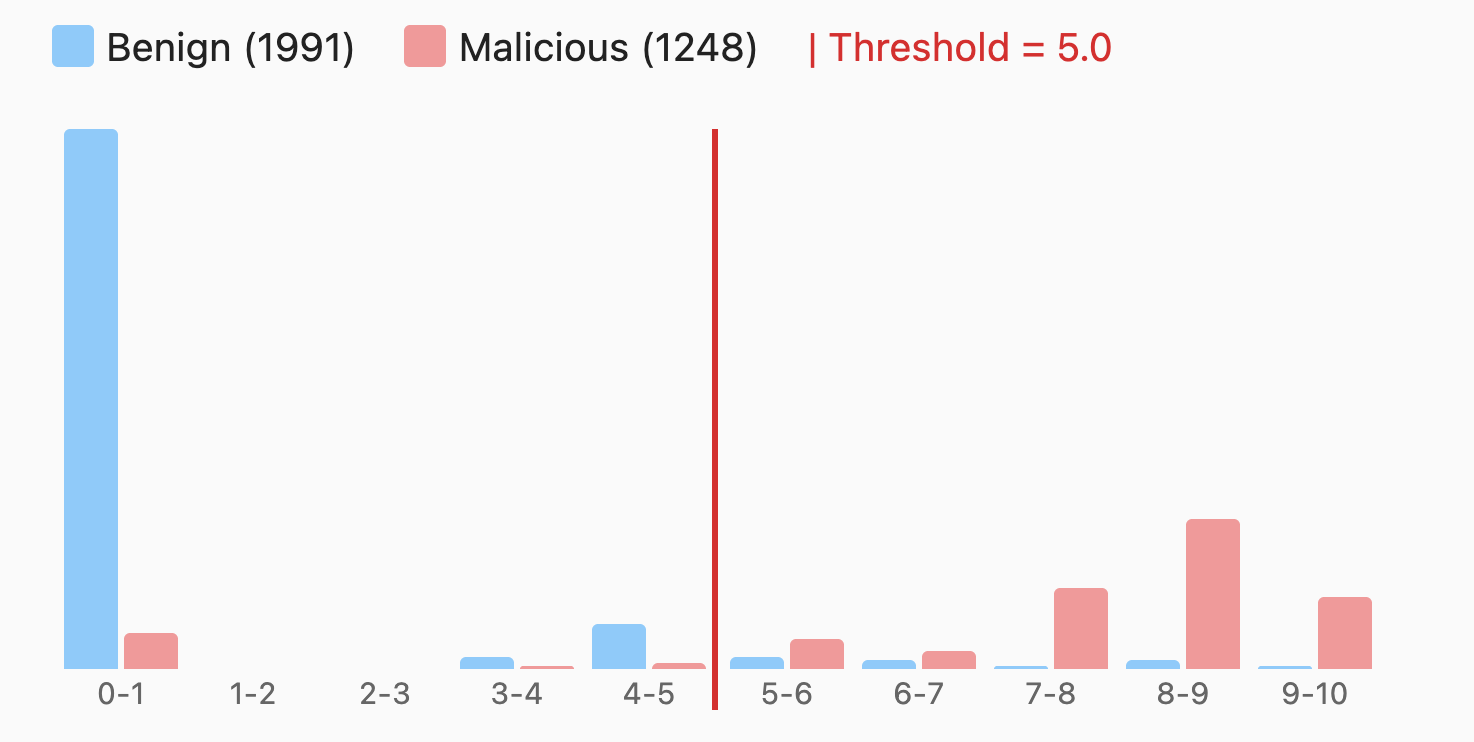
Sample output of an evaluation
Evaluations run nightly in CI, and developers and contributors can also run them locally. Below is sample output from an evaluation, as of commit 092675f:


Try GuardDog 3.0 today!
If you've read this far, you probably want to try GuardDog. It's easy to install:
# pip
pip install guarddog
# uv
uv tool install guarddogYou can then start scanning any npm or PyPI package. Try a legitimate one:
$ guarddog npm scan react
No risks found in react
────────────────────────────────────────
Assessment: No risks detected (0.0/10)
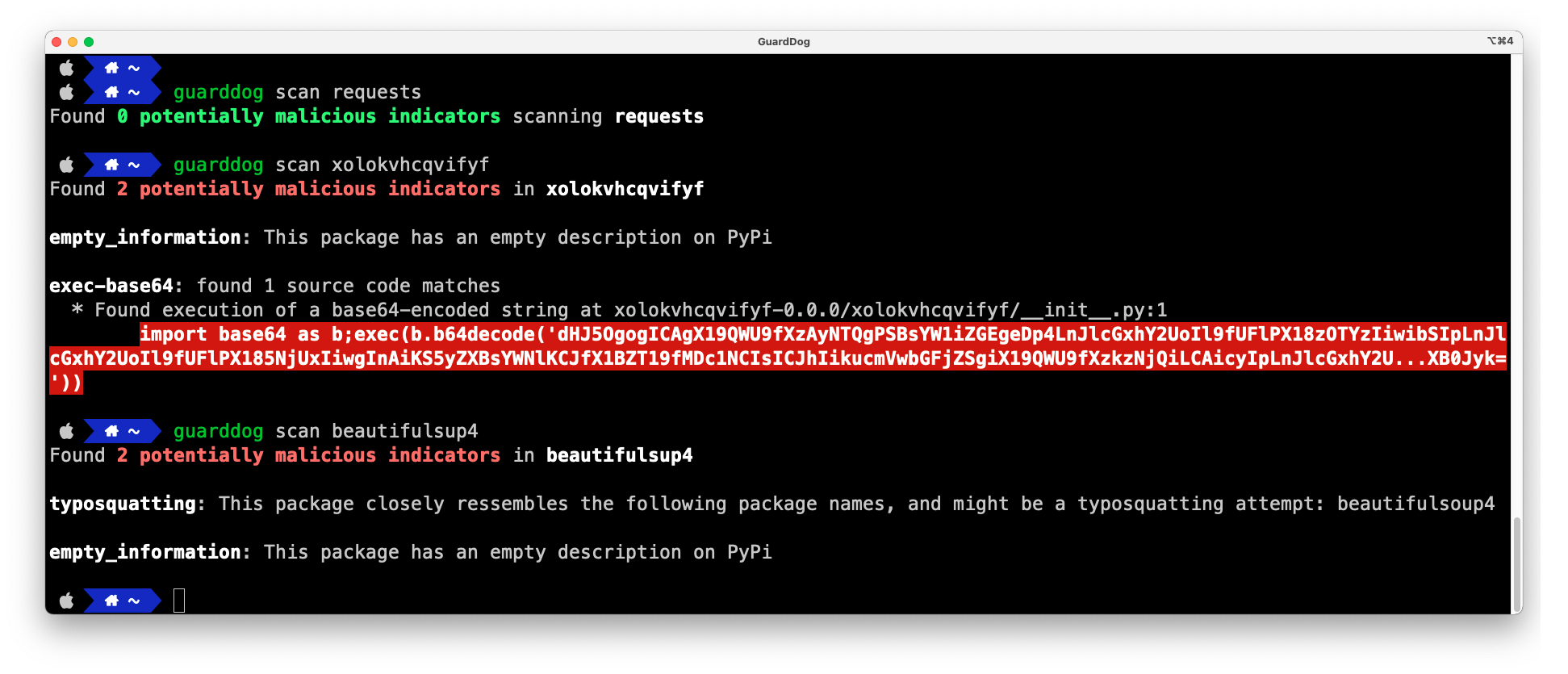
Try scanning a malicious one from our open source malicious software packages dataset:
$ URL=https://github.com/DataDog/malicious-software-packages-dataset/blob/main/samples/pypi/compromised_lib/litellm/1.82.7/2026-03-24-litellm-v1.82.7.zip
$ guarddog pypi scan $URL --zip-password infected
Scanning https://github.com/DataDog/malicious-software-packages-dataset/blob/main/samples/pypi/compromised_lib/litellm/1.82.7/2026-03-24-litellm-v1.82.7.zip, found 30 risks.
(...)
Assessment: High risk (10.0/10)You can also scan a requirements.txt or package.json file. GuardDog then scans each dependency:
guarddog npm verify my-project/package.jsonConclusion
Thank you for reading. We want to hear from you! We'd love to know about:
- Your experience with GuardDog 3.0
- Any recurring false positives you may run into
- Any false negative you may notice, especially on packages that are part of impactful campaigns (e.g., Shai-Hulud)
Reach us at securitylabs@datadoghq.com or open an issue on GitHub. You can also subscribe to our newsletter or RSS feed.
F.A.Q.
Does GuardDog use LLMs? No, GuardDog is a static analysis tool that doesn't use LLMs. However, it's a great tool to perform a first layer of triage before handing over a more in-depth investigation to an LLM. To read more about how we're achieving this at Datadog, see From single pull requests to full software packages: Detecting malicious code at scale on the Datadog Engineering blog.
Does GuardDog perform dynamic analysis? No, GuardDog does not attempt to run any code from packages it scans. This is a deliberate design choice that follows the Unix philosophy.
I'm a Datadog customer, can I integrate GuardDog with the Datadog platform? Yes, see the GuardDog integration for the Datadog Agent and the Cloud SIEM content pack.



